Vorhersagen in der Energiewirtschaft – Vergleich von konventionellen Machine Learning Methoden und Deep Learning
Die Vorhersage von Zeitreihen ist in der Energiewirtschaft von besonderer Bedeutung. Um beispielsweise frühzeitig Netzengpässe zu erkennen, benötigt man genaue Verbrauchs- aber auch Erzeugungsprognosen. Im Beitrag „Vorhersagen in der Energiewirtschaft – Welche Methoden eignen sich“ haben wir bereits diskutiert, welche Modelle sich für Zeitreihen mit bestimmten Charakteristika eignen. Meist gibt es nicht nur ein geeignetes Modell, so dass mehrere Methoden in Frage kommen, die jeweils Vor- und Nachteile für die spezifische Anwendung, für die man die Vorhersage anwenden will, aufweisen. Daher lohnt es sich, besonders bei den nicht-parametrischen Modellen genauer zu differenzieren und konventionelle Machine Learning Methoden mit Deep Learning Modellen zu vergleichen. Im Folgenden geht es daher weniger um die Eigenschaften der Zeitreihe, sondern mehr um die Modelle und ihre Eignung für eine bestimmte Anwendung.
Konventionelles Machine Learning
Unter konventionellem Machine Learning versteht man unter anderem [1, 2]:
- Linear Regression,
- Support Vector Machines (SVM),
- k-Nearest Neighbors (kNN),
- Decision Trees,
- Random Forrest,
- Boosting.
Der Beitrag wird insbesondere auf die Tree-Learning-Methoden und deren Boosting eingehen, weshalb es nur eine kurze Beschreibung der Vor- und Nachteile der anderen Methoden geben, und nicht tiefer auf ihre Funktionsweise eingegangen wird. Die folgenden Abschnitte stützen sich auf [1, 3, 4].
Linear Regression
Lineare Regression eignet sich gut, um große Datenmengen, einschließlich Zeitreihen, zu verarbeiten. Dabei sind sie besonders einfach zu implementieren, zu verstehen und zu interpretieren. Allerdings stößt sie an ihre Grenzen, wenn es nichtlineare Beziehungen zwischen den Merkmalen sog. Features (beispielsweise die Uhrzeit oder der Wochentag) und der vorhergesagten Variablen gibt. Daher kann erheblicher Aufwand erforderlich sein, um diejenigen Features zusammenzustellen, die einen möglichst linearen Zusammenhang aufweisen.
Support Vector Machines
Support Vector Machines (SVM) sind besonders geeignet für binäre Klassifikationsprobleme, sind jedoch auf binäre Probleme beschränkt. Sie können mit einer großen Anzahl von Features umgehen und sind robust gegenüber Overfitting. Allerdings sind sie ursprünglich nicht für Zeitreihen ausgelegt und können daher manchmal zeitliche Abhängigkeiten nicht gut erfassen. Darüber hinaus erfordern sie umfangreiche Datenvorbereitung und die Abstimmung von Hyperparametern.
k-Nearest Neighbors
Die k-Nearest Neighbors (kNN) Methoden sind geeignet für kleine Datenmengen, die ohne vorheriges Training schnell verarbeitet werden sollen, und sie können lokale Muster gut erkennen. Aus diesem Grund eignen sich kNN besonders für Echtzeitprognosen von Datenströmen, wenn die Rechenressourcen begrenzt sind. Bei größeren Datensätzen und vielen Merkmalen erweisen sich kNNs jedoch als rechenaufwendig. Darüber hinaus kann die Wahl des Werts für k schwierig sein, da sie zu over- oder underfitting führen kann. Abschließend haben kNNs Schwierigkeiten, komplexe und größere Muster zu erkennen und sie sind anfällig für zufälliges Rauschen in den Daten.
Decision Trees, Random Forrest, und Boosting
Decision Trees, auch Entscheidungsbäume genannt, und die daraus abgeleiteten Ensemble- und Boosting-Methoden weisen viele gemeinsame Eigenschaften auf. Daher werden sie gemeinsam betrachtet.
Decision Trees
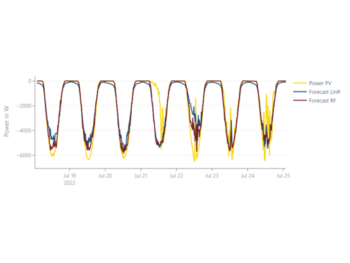
Decision Trees, wie der Name schon sagt, basieren darauf, dass Entscheidungsbäume anhand der bereitgestellten Trainingsdaten erstellt werden. Sie eignen sich gut, um auch nichtlineare Zusammenhänge in Zeitreihen zu erfassen und bleiben dabei interpretierbar. Darüber hinaus können sie mit fehlenden Daten und Ausreißern umgehen. Ein Nachteil von Entscheidungsbäumen ist jedoch, dass kleine Veränderungen in den Daten die Ergebnisse stark beeinflussen können und sie dazu neigen, sich an die Trainingsdaten „überanzupassen“ (Overfitting). Ein generelles Problem von Methoden, die auf Entscheidungsbäumen basieren, besteht darin, dass sie Schwierigkeiten haben, über die Trainingsdaten hinaus zu generalisieren (Abbildung 1). In Abbildung 1 sieht man, wie das auf einem Entscheidungsbaum basierte Modell zwar die saisonale Komponente lernt, jedoch nicht den linearen Trend, da Entscheidungsbäume nur Werte als Vorhersage wiedergeben, die bereits in den Trainingsdaten vorhanden waren.
Random Forrest
Das Problem des Overfittings von Entscheidungsbäumen kann durch die Bildung eines Ensembles aus mehreren Entscheidungsbäumen (Random Forest) verringert werden. Um nicht immer denselben Entscheidungsbaum zu verwenden und das Overfitting tatsächlich zu reduzieren, werden einzelne Bäume nur auf zufällige Teilmengen der Trainingsdaten und Features trainiert. Die Größe dieser Teilmengen, ebenso wie die Tiefe der Entscheidungsbäume (die Anzahl der Teilungen aufgrund von Entscheidungsregeln) und andere Parameter, können bei der Suche nach den besten Hyperparametern angepasst werden. Für die Vorhersage des Ensembles werden die Vorhersagen aller Entscheidungsbäume bei Regressionen gemittelt, während bei Klassifikationen das Ergebnis abgestimmt wird. Dieses Ensemble von Entscheidungsbäumen behält die meisten Stärken eines einzelnen Entscheidungsbaums bei. Die Trainingszeit wird jedoch länger, und das Modell wird komplexer in der Interpretation.
Boosting
Die Idee, ein Ensemble von Entscheidungsbäumen zu nutzen, wird bei Boosting-Methoden weiterentwickelt. Dabei werden viele weniger tiefe Entscheidungsbäume erstellt. Je nach Art der Erstellung und Gewichtung gibt es verschiedene Boosting-Methoden:
- Bagging (Bootstrap Aggregation): Ähnlich wie bei Random Forest werden verschiedene Teilmengen der Trainingsdaten verwendet, um die Entscheidungsbäume zu erstellen. Allerdings werden hier Teilmengen der Daten durch Bootstrapping, zufälliges Ziehen mit Zurücklegen, erstellt. Bei Regressionen werden am Ende die Vorhersagen aller Entscheidungsbäume gemittelt, während bei Klassifikationen das Ergebnis abgestimmt wird.
- AdaBoosting (Adaptive Boosting): Das Ziel von AdaBoosting ist es, nacheinander Entscheidungsbäume zu erstellen und dabei jeden Baum zu verbessern, indem die Gewichtung der Trainingsdaten angepasst wird. „Verbessern“ bedeutet in diesem Zusammenhang, die Loss-Funktion zu minimieren. Die Vorhersage jedes einzelnen Baumes wird je nach Leistung auf den Testdaten gewichtet und am Ende wird ein gewichtetes Mittel für Regressionen berechnet oder eine gewichtete Abstimmung für Klassifikationen durchgeführt.
- Gradient Boosting: Ähnlich wie bei AdaBoosting wird auch beim Gradient Boosting jeder neu erstellte Baum verbessert. Allerdings wird hier nicht die Loss-Funktion jedes einzelnen Baums optimiert, sondern die des gesamten Ensembles von Entscheidungsbäumen mithilfe eines Gradientenabstiegsverfahrens. Dabei wird auch die Gewichtung jedes einzelnen Baums optimiert. Für die Vorhersage des Ensembles wird ein gewichtetes Mittel für die Regression oder eine gewichtete Abstimmung für Klassifikationen gebildet.

Deep-Learning
Unter Deep Learning versteht man künstliche neuronale Netze (KNN) mit mehreren Schichten. Jede Schicht besteht aus Neuronen, die normalerweise von den Neuronen in der vorherigen Schicht abhängen. Für ein Neuron Nⱼ wird in der Regel zunächst eine gewichtete Summe aus den Werten der Neuronen der vorherigen Schicht xᵢ, und den Gewichten, wᵢⱼ, gebildet. Anschließend wird eine Aktivierungsfunktion ϕ verwendet, um nichtlineare Zusammenhänge in einem KNN darzustellen:
![]()
In der ersten Schicht können die Features und zusätzlich zurückliegende Abschnitte der Zeitreihe der Zielvariable als xᵢ verwendet werden anstelle der Neuronen der vorherigen Schicht. Häufig verwendete Aktivierungsfunktionen ϕ sind die ReLU-Funktion, der Tangens hyperbolicus oder die Sigmoid-Funktion. Ein einfaches KNN mit drei Schichten und unterschiedlicher Neuronenanzahl pro Schicht ist in Abbildung 2 dargestellt. Das KNN lernt genaue Vorhersagen zu treffen, indem die Loss-Funktion mithilfe der Backpropagation und des Gradientenabstiegsverfahrens minimiert wird.

Zusätzlich können die Neuronen auch Rückkopplungen haben. Solche Netze nennt man rekurrente neuronale Netze (RNN). Durch die Rückkopplungen wird das Netz mit einer Art von Gedächtnis ausgestattet, was das Lernen von Zusammenhängen zwischen vorherigen und neuen Vorhersagen des Modells ermöglicht. Ein typisches Beispiel für ein RNN ist ein LSTM (Long-Short Term Memory).
Eine der Stärken von Deep Learning bei der Vorhersage von Zeitreihen besteht darin, dass es komplexe Zusammenhänge in der Zeitreihe selbst erlernen kann. Man muss also nicht selbst nach Features in der Zeitreihe suchen, sondern die Deep Learning-Methoden erlernen diese. Allerdings geht dabei die Interpretierbarkeit verloren, da die Zusammenhänge in den Netzen häufig nicht mehr verständlich sind. Außerdem können Deep Learning-Modelle für große Datenmengen verwendet werden. Ohne große Datenmengen scheitern sie jedoch daran, meist komplexere Zusammenhänge zu erlernen. Deep Learning-Methoden können sich auch gut an Veränderungen der Muster durch neue Daten anpassen und diese durch erneutes Training erlernen. Allerdings sind Deep Learning-Modelle schwieriger zu trainieren und die Feinabstimmung der Hyperparameter kann unter Umständen sehr aufwendig sein. [5, 6]
Vergleich der Modelle
Sowohl die auf Entscheidungsbäumen basierenden Boosting Methoden als auch Deep Learning Methoden können gute Ergebnisse bei der Vorhersage von Zeitreihen erzielen. Deshalb lohnt es sich, diese Modelle zu vergleichen, um ihre Eignung für verschiedene Anwendungsfälle zu bewerten.
Anforderungen an Trainingsdaten und Features
Die Anforderungen an Trainingsdaten und Features variieren je nach verwendetem Methodentyp, seien es auf Entscheidungsbäumen basierende Methoden oder Deep Learning.
Für auf einem Entscheidungsbaum basierende Methoden müssen die Trainingsdaten klar strukturiert sein und bestehen aus Beobachtungen der Zielvariable und den dazugehörigen Features. Die Identifikation zeitlicher Abhängigkeiten in den Daten erfordert bei Entscheidungsbäumen die gezielte Schaffung geeigneter Features und die Auswahl passender Modelle. Auf dem Entscheidungsbaum basierende Methoden eignen sich daher gut für Zeitreihen, bei denen wichtige Merkmale leicht zu identifizieren sind. Hierbei hilft es, wenn man über sogenanntes Domain-Knowledge (Fachwissen) verfügt und entsprechende Features für den jeweiligen Anwendungsfall ableiten kann. Auf Entscheidungsbäumen basierende Methoden zeichnen sich durch ihre Effizienz und die vergleichsweise kurze Trainingsdauer aus.
Im Gegensatz dazu können Deep-Learning-Methoden unstrukturiertere Daten nutzen und ermöglichen auch die gleichzeitige Vorhersage mehrerer Ergebnisse. Sie lernen wichtige Features aus den unstrukturierten Daten und sind in der Lage, zeitliche Zusammenhänge in den Daten zu erkennen. Deep Learning kann komplexe Abhängigkeiten innerhalb von Zeitreihen und deren Features erkennen, was in einigen Anwendungen von Vorteil ist. Allerdings erfordern Deep Learning-Methoden in der Regel eine beträchtliche Datenmenge, Feinabstimmung der Hyperparameter und eine lange Trainingszeit, um optimal zu funktionieren. Mit der zunehmenden mathematischen Komplexität der Deep Learning-Methoden, steigt auch deren programmiertechnischer Implementierungsaufwand, sofern keine „low-code“ oder „AutoML“-Bibliotheken verwendet werden.
Quantilvorhersagen
In vielen Anwendungen ist es von Interesse, Bereiche festzulegen, innerhalb derer sich die Zielvariable befinden sollte. Dies kann beispielsweise wichtig sein, um mit einer bestimmten Sicherheit vorherzusagen, wie hoch die Spitzenlast sein wird. Um solche Wahrscheinlichkeitsaussagen zu treffen, kann man Quantilvorhersagen verwenden.
Für entscheidungsbaumbasierte Methoden, die aus vielen Entscheidungsbäumen bestehen, gestaltet sich dies vergleichsweise einfach. Man erhält bereits eine Verteilung für die Zielvariable durch die vielen verschiedenen Vorhersagen der einzelnen Entscheidungsbäume. Indem man nun die Abstimmung der Entscheidungsbäume anpasst und nicht den Mittelwert, sondern Quantile verwendet, lassen sich Quantile bestimmen, ohne ein zusätzliches Modell zu trainieren. Bei Gradient Boosting hingegen muss ein neues Modell erstellt werden, da das gesamte Ensemble auf die Loss-Funktion optimiert ist. In diesem Fall ist es notwendig, die Loss-Funktion anzupassen und ein neues Modell für jedes gewünschte Quantil zu trainieren. Ähnliches wäre auch bei anderen entscheidungsbaumbasierten Methoden möglich.
Im Bereich des Deep Learnings bietet sich einerseits die Möglichkeit, durch das Zufallselement „Dropout,“ also das zufällige, temporäre Deaktivieren von Neuronen eine Wahrscheinlichkeitsverteilung der Vorhersage zu erzeugen. Hierfür sind jedoch zahlreiche Vorhersagen mit verschiedenen Dropout-Einstellungen erforderlich. Die andere Möglichkeit besteht darin, auch hier die Verlustfunktion anzupassen und ein Modell für jedes gewünschte Quantil zu erstellen. Beide Methoden erfordern erheblichen rechnerischen Aufwand.
Multi-Step Forecasting
Häufig ist es notwendig, nicht nur einen Zeitschritt in die Zukunft vorherzusagen. Zum Beispiel müssen, um den Intraday-Energiepreis für den gesamten kommenden Tag vorherzusagen, alle 96 Zeitschritte des folgenden Tages prognostiziert werden, da die Daten in 15-minütigen Intervallen verfügbar sind.
Deep Learning-Methoden ermöglichen eine einfache Anpassung der Anzahl der Vorhersagen, indem die Neuronenanzahl in der letzten Schicht dem gewünschten Ausgang angepasst wird. Dadurch können alle Zeitschritte gleichzeitig vorhergesagt werden, wobei mögliche Zusammenhänge zwischen den einzelnen Zeitschritten erhalten bleiben und die zuletzt übermittelten Daten für alle Zeitschritte genutzt werden können.
Bei entscheidungsbaumbasierten Methoden gestaltet sich dies komplizierter. Es gibt verschiedene Ansätze, um mehrere Zeitschritte vorherzusagen. Angenommen, wir möchten n Zeitschritte vorhersagen: Die einfachste Möglichkeit besteht darin, ein Modell zu trainieren, das keine Features enthält, die Daten verwenden, die weniger als n Zeitschritte zurückliegen. Andernfalls würden Daten verwendet, die in einem zukünftigen Zeitpunkt liegen (Abbildung 3a). Dies hat jedoch zur Folge, dass die neuesten Daten von den meisten Zeitpunkten nicht als Features genutzt werden.
Um diese Daten zu nutzen, kann man rekursiv Vorhersagen erstellen, bei denen die zuvor getroffenen Vorhersagen als Features für die folgenden Vorhersagen verwendet werden (Abbildung 3b). Hierbei besteht jedoch die Gefahr, dass Fehler in den Vorhersagen sich fortsetzen und bei weiter in der Zukunft liegenden Vorhersagen zu großen Fehlern führen. Eine Möglichkeit, dies zu umgehen, besteht darin, für jeden Zeitschritt ein individuelles Modell zu trainieren (Abbildung 3c). Dadurch können die neuesten Daten verwendet werden, während gleichzeitig nur tatsächlich gemessene Daten verwendet werden, was die Fehlerfortpflanzung verhindert. Dieser Ansatz ist jedoch rechenaufwendiger, da n Modelle erstellt werden müssen. [7]

Zusammenfassung
Die Vorhersage von Zeitreihen in der Energiewirtschaft ist entscheidend für eine Vielzahl von Anwendungsfällen, wie Beispielsweise Netzengpässe frühzeitig zu erkennen und genaue Prognosen für die Erzeugung von Erneuerbaren Energien zu erstellen. Bei nicht-parametrischen Modellen lohnt es sich, konventionelle Machine-Learning-Methoden mit Deep Learning zu vergleichen. Für konventionelle Machine-Learning-Methoden sind strukturierte Trainingsdaten notwendig, während Deep Learning unstrukturierte Daten verarbeiten und aus diesen die wichtigen Features finden und erlernen kann. Quantilvorhersagen erfordern Anpassungen, wobei bei Entscheidungsbaum-basierten Methoden die Vorhersage der Quantile im Vergleich zu Deep Learning einfacher ist. Beim Multi-Step Forecasting passen Deep Learning-Modelle die Anzahl der Vorhersagen flexibel an, während Entscheidungsbaum-Methoden verschiedene Ansätze erfordern. Die Wahl des geeigneten Modells hängt von der Anwendung und den Daten ab.
Weitere Informationen
- Vorhersagen in der Energiewirtschaft – Tutorial zur Vorhersage von Haushalts- und PV-Lastgängen
- Vorhersagen in der Energiewirtschaft – Welche Fehlermetriken eignen sich?
- Grundlagen künstlicher Intelligenz und Machine Learning in der Energiewirtschaft
- Anwendungsfälle von Supervised Machine Learning in der Energiewirtschaft
- Supervised Machine Learning
- Bidirektionales Lademanagement (BDL)
Literatur
[1] Russell, S., & Norvig, P. (2021). Artificial Intelligence: A Modern Approach (4th ed.). Prentice Hall.
[2] Chauhan, N. K., & Singh, K. (2018). A Review on Conventional Machine Learning vs Deep Learning. In 2018 International Conference on Computing, Power and Communication Technologies (GUCON) (pp. 347-352). doi: 10.1109/GUCON.2018.8675097.
[3] Müller, A. C., & Guido, S. (2016). Introduction to Machine Learning with Python: A Guide for Data Scientists. O’Reilly Media, Inc.
[4] Géron, A. (2022). Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow. O’Reilly Media, Inc.
[5] Brownlee, J. (2018). Deep Learning for Time Series Forecasting: Predict the Future with MLPs, CNNs, and LSTMs in Python. Machine Learning Mastery.
[6] Gamboa, J. C. B. (2017). Deep Learning for Time-Series Analysis. arXiv preprint arXiv:1701.01887.
[7] Bontempi, G., Ben Taieb, S., & Le Borgne, Y. A. (2013). Machine Learning Strategies for Time Series Forecasting. In Business Intelligence: Second European Summer School, eBISS 2012 (pp. 62-77).
[8] Haben, S., Voss, M., & Holderbaum, W. (2023). Core Concepts and Methods in Load Forecasting: With Applications in Distribution Networks. Springer Nature.
[9] Mahalakshmi, G., Sridevi, S., & Rajaram, S. (2016, January). A Survey on Forecasting of Time Series Data. In 2016 International Conference on Computing Technologies and Intelligent Data Engineering (ICCTIDE’16) (pp. 1-8). IEEE.